标注
sql
测试用例
PID
Thread Pool
健身私教预约系统
iVX低代码平台
kaggle
scikit-learn
入门
加锁原理
火车票识别系统
babel
玫瑰花
ADI DSP中文资料
凝思磐石
反编译工具
PushFront
ws-discovery
小波阈值降噪
大模型训练
2025/2/9 0:52:35
从零开始搭建本地安全 AI 大模型攻防知识库
本文将系统分享从零开始搭建本地大模型问答知识库过程中所遇到的问题及其解决方案。
1 概述
目前,搭建大语言问答知识库能采用的方法主要包括微调模型、再次训练模型以及增强检索生成(RAG,Retrieval Augmented Generation)三种方…

百度大模型构建智能问答系统技术实践
背景
随着大模型的飞速发展, AI 技术开始在更多场景中普及。在数据库运维领域,我们的目标是将专家系统和 AI 原生技术相融合,帮助数据库运维工程师高效获取数据库知识,并做出快速准确的运维决策。
传统的运维知识库系统主要采用…
一文速读 LLaMA3.2-Vision 模型的结构
随着 Meta 放出了 LLaMA3.2 系列模型,LLaMA 系列也是正式迎来了官方版本的多模态大模型 LLaMA3.2-Vision [1]。那我们就在本期内容中聊一聊 LLaMA3.2-Vision 模型的结构,希望对大家有所帮助。
相关代码位于 [2]
结论
先说结论,LLaMA3.2 的…
转做大模型开发,能不能挽救职业生涯?
大模型算是当之无愧最火的一个方向了,算是新时代的风口。有小伙伴觉得,既然是新领域、新方向,那么,人才需求肯定比较大,相应的人才缺乏,竞争也会更少,那转行去做大模型是不是一个更好的选择呢&a…

Google Tensorflow总监力荐|一本书掌握谷歌深度学习框架
今天向大家分享一本好书,由黄文坚、唐源编撰的 《TensorFlow实战》,这本书主要从实战的角度手把手教你使用TensorFlow,实现你想要的功能。需要的同学可以直接滑动到文章底部查看本书PDF版本的领取方式。TensorFlow的版本在不断更新换代&#…

【DeepSeek-R1训练笔记】随手记录一些训练log
背景说明
DeepSeek系列解读请移步我的上一篇blog:【完整版】DeepSeek-R1大模型学习笔记(架构、训练、Infra)代码仓库【科大的大四老哥太太太太太值得倾佩了】:https://github.com/Unakar/Logic-RLDeepSeek-R1-Zero复现文档&#…

在LangChain中初识向量数据库-LLM与向量数据库的惺惺相惜
引言
在学习与使用LangChain的过程中,接触到了向量数据库,通过为大语言模型提供一个自己的语料库,可以让模型的回复结果都从语料库中来,这样模型就可以回答一些它不知道的问题.但对向量数据库的概念并不熟悉,所以仔细了解一下什么是向量数据库
向量数据库的概念
简单介绍向量…

【AI知识点】泛化(Generalization)与过拟合(Overfitting)
泛化(generalization) 是机器学习中的一个核心概念,指的是模型在训练数据之外的新数据上表现得如何。换句话说,泛化能力衡量的是模型能否在未见过的样本上做出正确的预测或推断。
1. 泛化的背景
当我们训练机器学习模型时&#…
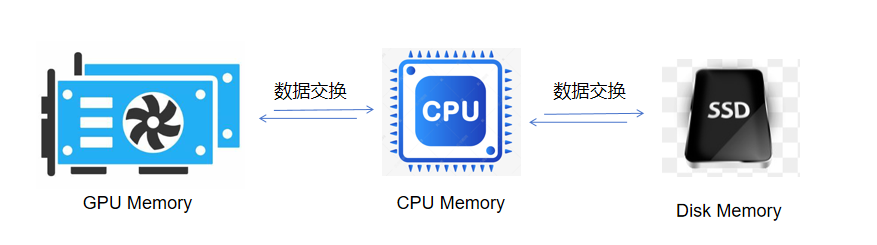
极智AI | Colossal-AI高效异构内存管理系统
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文来介绍一下 Colossal-AI高效异构内存管理系统。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq 首先需要了解一下异构内存中的…

LlamaFactory可视化微调大模型 - 参数详解
LlamaFactory 前言
LLaMA Factory 是一个用于微调大型语言模型的强大工具,特别是针对 LLaMA 系列模型。
可以适应不同的模型架构和大小。
支持多种微调技术,如全参数微调、LoRA( Low-Rank Adaptation )、QLoRA( Quantized LoRA )等。
还给我们提供了简单实用的命令行…
大模型的高考数学成绩单:及格已经非常好了
让考生头皮发麻的高考数学,可难倒了顶尖 AI 大模型。
一年一度的高考即将落幕,衷心希望各位考生都超常发挥,考出满意的好成绩!!
和往年一样,除了让 AI 大模型写写高考作文,我们也选取了六家国…
GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-如何用自己数据微调ChatGLM2模型训练 目录 GPT实战系列-如何用自己数据微调ChatGLM2模型训练1、训练数据广告文案生成模型训练和测试数据组织: 2、训练脚本3、执行训练调整运行 4、问题解决问题一问题二问题三问题四 1、训练数据
广告文案生成模型
输…

在多机多卡训练时,保存的文件无法读取,报错文件已经损坏
问题描述:多机多卡训练保存了optimizer.pt文件,但是该文件在被读取时显示已经损坏。 原来的报错:
Traceback (most recent call last):File "/mnt/petrelfs/tongjingqi/train-moe/smoe/entrypoint/cpt_fpt.py", line 280, in <…

GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF 文章目录 GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHFPretraining 预训练阶段Supervised FineTuning (SFT&#x…
点击率预测模型Embedding层的学习和训练
导读: 本文将简要介绍推荐模型的发展历史,现状,和下一步的研究趋势。并重点介绍针对embedding数据的模型训练及优化。主要包含以下几大部分内容:
CTR预测模型(CTR Models)连续值处理(Continuou…
初识 Embedding,为何大家都基于它搭建私人智能客服?
随着 AI 技术的发展,大家在日常使用过程中经常会碰到一些目前 GPT4 也无法解决的问题:
无法获取个人私有数据信息,进行智能问答无法获取最新信息,LLM 模型训练都是都是有截止日期的无法定制化私有的专属模型,从而在某…
交通控制系统中的 Prompt工程:引导LLMs实现高效交叉口管理 !
本研究提出了一种新型的交通控制系统方法,通过使用大型语言模型(LLMs)作为交通控制器。该研究利用它们的逻辑推理、场景理解和决策能力,实时优化通行能力并提供基于交通状况的反馈。LLMs将传统的分散式交通控制过程集中化…
RAG数据集自动构造探索, 附prompt
从文档中手动创建数百个 QA(问题-上下文-答案)样本可能非常耗时且劳动密集。此外,人工生成的问题可能难以达到全面评估所需的复杂程度,最终影响评估的质量。通过使用合成数据生成,开发人员在数据聚合过程中的时间可以减…
Ollama 本地运行大模型(LLM)完全指南
文章介绍了 Ollama 本地运行大模型(LLM)的方方面面, 包括安装运行、对话、自定义模型、系统提示配置、调试、开发、存储、如何作为服务、OpenAI 的兼容等。
这一年来,我已经习惯了使用线上大模型 API 来工作,只要网络…
【大模型技术】什么时候需要训练和微调属于自己的大模型——小微企业必须要明白的问题
“ 从问题出发,先有需求再有解决方案 ”
老板和员工在思维方式上有一个很大的差别就是,作为老板他们喜欢寻找现有的解决方案,如果现有的解决方案无法满足的情况下,才会自己设计一个解决方案。
而作为员工来说特别是技术人员&…
SparkRA带你读论文 | 如何训练数据高效的 LLMs
简介 How to Train Data-Efficient LLMs
论文作者: Noveen Sachdeva, Benjamin Coleman, Wang-Cheng Kang, Jianmo Ni, Lichan Hong Ed H. Chi, James Caverlee, Julian McAuley, Derek Zhiyuan Cheng
论文链接:
https://arxiv.org/pdf/2402.09668.pd…
无监督3D场景理解,LLM 在 3D 场景理解中的应用与探索 !
构建能够理解和推理3D场景的模型很难,原因在于缺乏3D监督训练的数据来源和大规模训练策略。 在这项工作中,作者问到:在没有3D预训练的情况下,预训练语言模型中的知识如何被利用来理解和推理3D场景? 本工作的目标是确定…
AI大语言模型之分布式训练概述
一、前言
随着语言模型参数量和所需训练数据量的急速增长,单个机器上有限的资源已无法满足大语言模型训练的要求。需要设计分布式训练(Distributed Training)系统来解决海量的计算和内存资源需求问题。
在分布式训练系统环境下需要将一个模…
MegaScale:万级GPU集群中大模型训练
论文链接:https://arxiv.org/abs/2402.15627
MegaScale系统简介
MegaScale是一个专为在超过10,000个GPU上训练大型语言模型(LLMs)而设计的生产系统。该系统通过算法和系统组件的协同设计,解决了大规模训练中的效率和稳定性挑战&…
AI 大模型训练中,通常会采用哪些方法?(输入篇)
大家好
某种程度来说大模型训练的核心算法就是300到400行代码,如果真正理解了并不难。下面我将带大家分析常规大模型训练有几个阶段以及在训练中一般会用到哪些方法。 由上图可以看出,大模型训练主要有四个阶段:预训练、有监督微调、奖励建模…
冷思考:低代码的AI Agent构建平台能创造价值吗?
当前AI 圈中热点讨论的产品,除了以ChatGPT为代表的Chatbot领域,以及以Character.ai 为代表的AI虚拟社交领域,另一个热度较高的领域就是AI Agent领域。
大模型发展到今天,已经基本达成了一个共识:错综复杂的工作任务无…
做情绪识别,有必要用LLM吗?
情绪识别在各种对话场景中具有广泛的应用价值。例如,在社交媒体中,可以通过对评论进行情感分析来了解用户的情绪态度;在人工客服中,可以对客户的情绪进行分析,以更好地满足其需求。
此外,情绪识别还可以应…
『大模型笔记』常见的分布式并行策略(分布式训练)
常见的分布式并行策略(分布式训练) 文章目录 一. 为什么分布式训练越来越流行二. 常见的并行策略2.1 数据并行2.2 模型并行2.3 流水并行2.4 混合并行二. 参考文献一. 为什么分布式训练越来越流行 近年来,深度学习被广泛应用到各个领域,包括计算机视觉、语言理解、语音识别、广…
OpenAI大模型项目计划表(InsCode AI 创作助手)
OpenAI大模型项目计划表
阶段任务负责人开始日期完成日期立项确定项目目标和范围项目经理2023-05-012023-05-03确定项目团队和资源项目经理2023-05-042023-05-05确定项目时间表和里程碑项目经理2023-05-062023-05-10数据收集收集训练数据和标注数据团队2023-05-112023-05-20确…